- MISSION+
- Posts
- May 2025 - Reality Over Hype
May 2025 - Reality Over Hype
MISSION+
May 07, 2025

For those of us that build mobile apps, the “Apple tax” (a levy on all payments for an app to be allowed into the Apple ecosystem) has been a dull pain we have learnt to live with. Perhaps no longer. A US judge has recently ruled no more fees on purchases made on outside purchases, and more importantly: no more restrictions on developers giving instructions or links to non-app payment or signup flows. Major win.
Earlier this week, OpenAI agreed to buy Windsurf - the AI coding platform - for US$ 3 billion. For the uninitiated, Windsurf is like Cursor; it’s not vibe-coding, but aims to make developers much more effective.

In some ways, this should ground us on the current state of AI assisted delivery. OpenAI claims their models to be within the top 50 programmers on the planet. If that were true, they would simply get the model to produce their own AI coding platform - they certainly have the distribution channel for it! But… it’s not true.
Furthermore, OpenAI is in one of the best positions in the world to determine if & when AI models will render engineers redundant. That they will spend $3B on a tool for developers tells us that it isn’t any time soon.
Increasingly, we as technology leaders, startup founders, and engineers need to use our critical judgment to separate the claims from the reality. The world is changing. We don’t need to hype it.

Reflections On The Mission
I recently moderated a panel discussion on innovation within the sustainability space, and one of the participants made an interesting comment. His concern was around the efficiency of AI models, and how wasteful it is using very large models for very simple tasks.
The point was not that we shouldn’t use state of the art models, but rather that having some kind of metric around efficiency would help us judge when to use what. A little like the European Union energy label or Nutri-Grade.

The first thing we must be clear about is inference vs training. When an AI model is ‘trained’, it is given huge amounts of data from which the model learns over a period of time. The amount of time is often not public - but Facebook’s Llama does publish theirs - 54 days on a huge array of NVIDIA GPUs! But, this is a one-off: once the model is trained, that’s it (for that model).
Inference on the other hand occurs every single time the model is used - whether for a prediction, a forecast or a classification. So over the lifetime of a model, this is the more important activity to track.
Now before we go much further on this, I do want to stress caution - the individual use of AI for inference is not particularly carbon heavy:
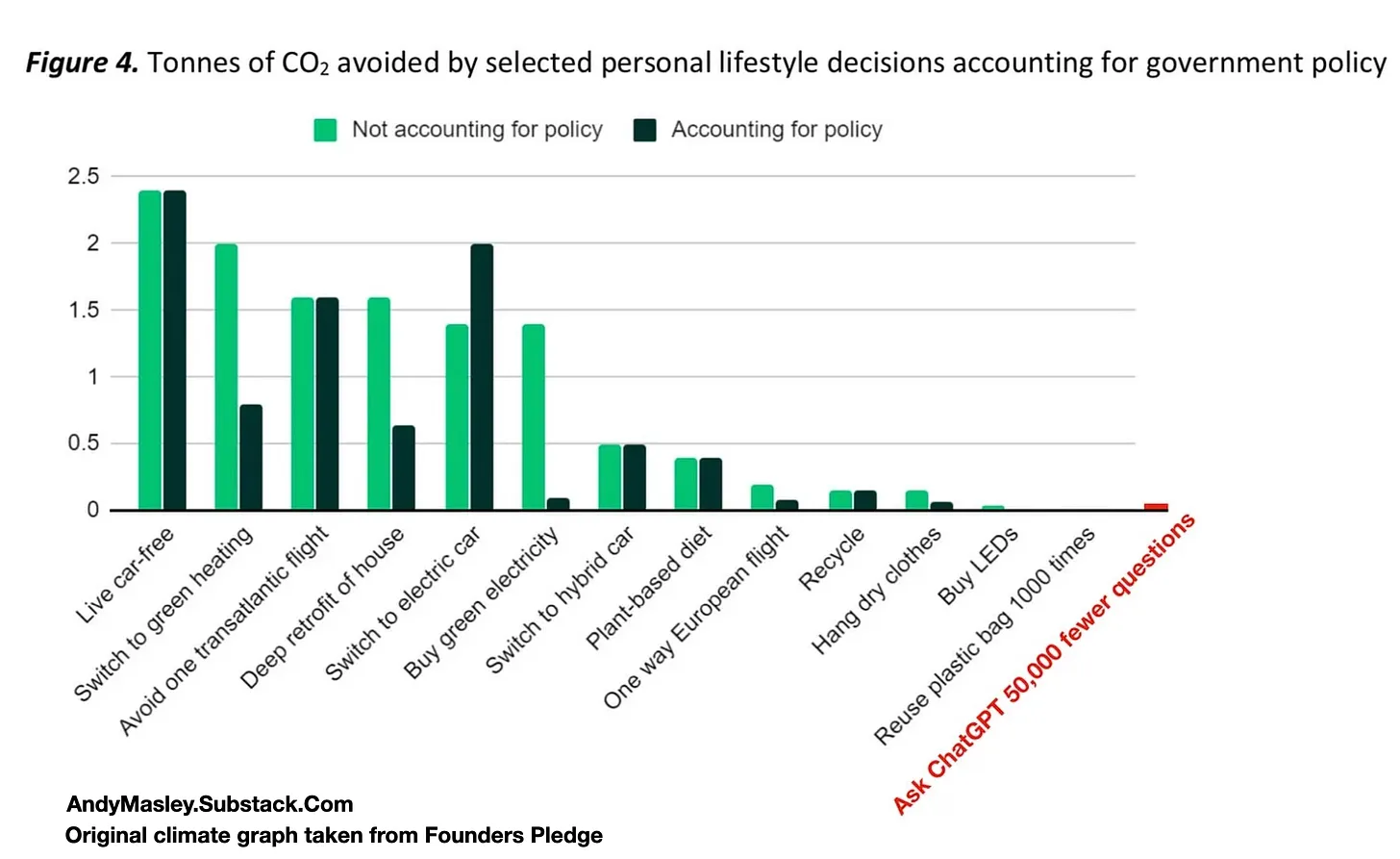
With that caveat out of the way, what would influence the efficiency of our AI usage?
Let’s start with model efficiency. When Deepseek R1 was launched at the end of January, many observers were shocked that it claimed to use up to 90% less energy/compute than other equivalent models (although skepticism around those numbers persists). How is that possible?

A substantial part of that is due to an architectural feature that allows only part of the model to be ‘active’ at any given time (approximately only 6%). Other technical tricks were used to reduce the amount of data that needed to be held in memory, and reducing precision of intermediary transformer ‘layers’ (without sacrificing output precision).
In addition to general model efficiency, a rising trend is so-called “Small Language Models”. These are efficient, targeted models that run on much more accessible infrastructure. These can be further split into two groups:
Generalised small language models - which are less powerful than their larger kin, but perhaps adequate for the task at hand. Most of the common LLMs have small versions, for example Google’s Gemma, Meta’s Llama 4 Scout or Mistral’s Small 3.1.
Specialised small language models - which are focused on a particular domain, and may perform as well (or even better) than a large language model, but only within that niche. This is achieved through training & fine tuning on specific datasets, and ignoring the rest.
By choosing - or creating - the correct small language model, huge efficiencies can be achieved if the use cases are relatively fixed.
Finally, and perhaps most interestingly, is the infrastructure that the model runs on. NVIDIA has such a tight association with AI that its stock price practically multiplied by ten since ChatGPT was launched, only to get hammered by the (unfounded in my opinion) fear that DeepSeek meant the end of NVIDIA’s growth. I have many reasons to think that NVIDIA is overvalued and fragile, but DeepSeek (a model trained on NVIDIA’s GPUs!) is not one of them.
But it’s not the only game in town. It speaks to Google’s dominance that their custom AI chip - the TPU (Tensor Processing Unit) - is pretty much just accepted as being state of the art, and when Apple announces that their (admittedly disappointing) models are 100% trained on TPUs, the market didn’t blink. Unlike DeepSeek, which was trained on NVIDIA. Anyway…
TPUs boast an approx 2.5 price/performance (and therefore carbon emission) ratio over NVIDIA. But one of the TPU’s creators, Jonathan Ross, was not satisfied. He went on to create Groq, and their LPU (Language Processing Unit) offering. The LPU is a further 10x more efficient than the TPU, so anything up to 25x more efficient than an NVIDIA GPU. Now that is something which should be putting a dent in the NVIDIA stock price.

Put it all together - efficient models, right-sized for the use case, running on efficient infrastructure - and you score yourself an A on the rating of AI efficiency!
Interesting Articles
futurism.com/professors-company-ai-agents - Carnegie Mellon University created a fake company staffed only by AI Agents. The results were disastrous. Hyperventilating hype merchants shocked, technologists roll their eyes.
https://www.promptly.fyi/library - as I rule I’m pretty skeptical on prompt engineering, putting it in the same category as “being good with Google” (or Google-fu as we used to call it) was 15 years ago. Over time, the search engines build a profile of your search habits, and “know” what you want. Prompting will probably go a similar way. Until then, libraries like this provide guidance and starting points for your explorations.
https://www.youtube.com/watch?v=StLp4Z-ul44 - the Unitree Robotics G1 robot boxing a human. What could possibly go wrong? Apparently live-streamed robot boxing fights are coming soon…
State of the art AI videos: Harry Potter - North Korea Wizard, Snow White starring Samuel Jackson WINS BEST PICTURE!, Star Wars Reggae.
This Is The Way

Feature A Fractional
We’re On A Mission


Until next month,
Ned & the MISSION+ team
P.S. If you would like to bring the MISSION+ team into your organisation to help, please reach out to [email protected]!
Enjoyed this? Share this with a friend who might too!