- MISSION+
- Posts
- November 2025 — Beyond Prompt Engineering
November 2025 — Beyond Prompt Engineering
MISSION+
November 05, 2025

It’s been a hard month for the hyperscalers. AWS had a massive outage that basically brought down the internet, then Azure managed to follow suit right before a Microsoft earnings report.
I’ve heard a couple of naive souls gloat about these outages… Oh my sweet summer child! We never take pleasure in other company’s infrastructure downtime. Behind all the marketing, the poor bastard trying to get stuff back online is someone just like you or me. He or she is doing their best to get things back up and minimise the impact on those who depend on it.
Worse, you’re tempting the gods. Infrastructure and low level provisioning is hard - we should feel empathy, not amusement, at the woes of others. Instead, we should approach every outage as an opportunity to learn more about distributed systems, where they go wrong, and where it is cost-effective to prevent problems.
After all, there are only two kinds of companies: those who’ve had an outage, and those who will.

MISSION+ Update
The circus is back in town. For those of you in Singapore, the 10th FinTech Festival is just around the corner! Our CTO Ned will be moderating a panel on Agentic Commerce: Solving for Trust, Transparency, and Commercial Models.
After a long day furiously finteching, you’ll need to switch it up - so mosey on down to our evening event:

We look forward to seeing you at both events - it’s going to be a fun week for sure!
Reflections On The Mission
The idea of the “prompt engineer” has never quite sat well with me. It is undoubtedly true that some prompts are better than others, but the concept didn’t quite fit. Not least because AI can be used to “improve” or augment a prompt, and most modern LLMs automatically do that for you anyway.
It all smelt a bit like “Google fu”. In the early 2000s, a person could be “good” at using Google by knowing how to structure a Google query, or through the use of optional operands such as “-” (exclude term), “OR” (search independently for two words), or “daterange” (when the page was indexed). Over time, these became redundant as Google got better at figuring out what you - and specifically you - wanted.
“Context engineering” on the other hand immediately resonates. When reframed in this new terminology, the benefits and pitfalls of how you have structured the context window becomes more obvious.
A model’s context window is made up from the system prompt (the fixed setup provided by the model) and the user prompt. That user prompt is effectively “programming” the model, and guides the response. In a conversation with a model, each message adds to that window - that’s how it knows what has already been said, and retains conversational memory.
Retrieval Augmented Generation (RAG) extends this idea: all we are really doing is allowing the system to try and find additional information to inject into the user prompt - for example the relevant section from your FAQs for a question.
But the context window for each model has a fixed upper size limit; plus the larger it is, the more tokens consumed (and therefore the cost increases). Quality of response also deteriorates as the context window gets filled up - facts and details get lost. If not, we wouldn’t need RAG, we would simply dump every piece of organisational knowledge into context.
Enter the context engineer. Through best practices, tooling and experience, they become experts at populating the context window with sufficient knowledge to drive an optimal balance of output quality vs cost & accuracy.
Areas of context window engineering I see developing include:
Knowledge management “plugins” for agents, potentially via MCP, for RAG-style context augmentation
Organisation-wide prompts that set style, guardrails, and shared knowledge, that are added to every query
Memory - LLMs don’t “learn” over time, but agent learnings could be added to a memory sub-component, which is then dynamically added to the context window (e.g. Mem0 or Letta)
Personalisation - one’s own preferences could be added to the window. Perhaps we own a “personalisation wallet” that can be accessed by authorised agents?
Auto-compaction of the context window - there will be redundancy in the content of the window, and the models will get better at compacting that automatically.
Plus of course the skills and experience of the context engineers themselves
All of this runs much deeper than simply writing better prompts. Over time, our ability to understand, shape and manipulate the context window will improve - just as the window itself gets larger, cheaper and more accurate.
Prompt engineering was a skill. Context engineering is the profession.
P.S. We missed an opportunity to call the context window the attention span. So be it.
Interesting Articles
Everything Is Becoming a Bank - everything is a bank. Even airplanes.
Why do AI company logos look like buttholes? - I… I have nothing to add.
Developer Productivity AI Arena - which AI coding models actually perform the best in real-world scenarios? LET THEM FIGHT.
This Is The Way
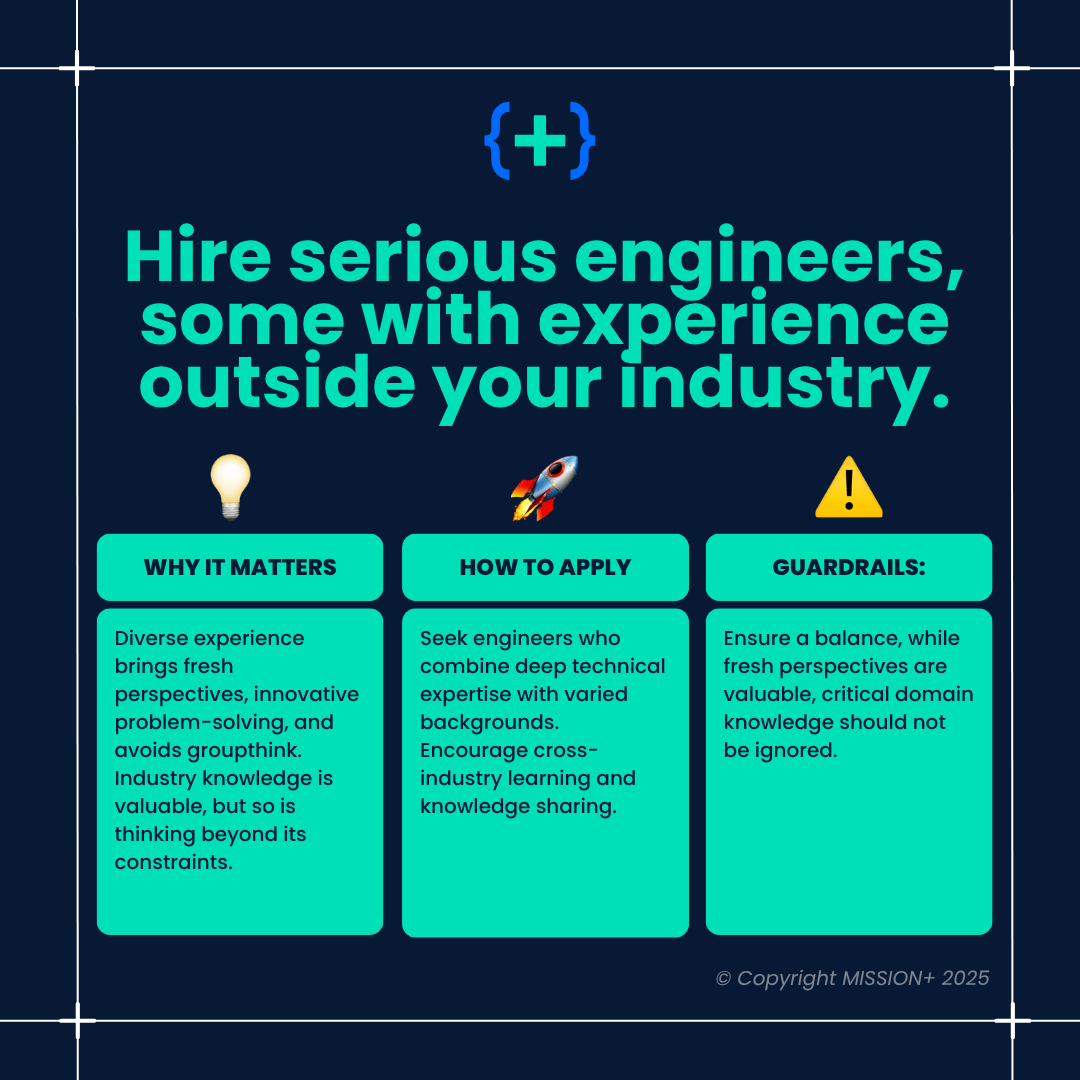
Feature A Fractional

We’re On A Mission


Until next month. Together, We Build {+}
Ned & the MISSION+ team
P.S. If you would like to bring the MISSION+ team into your organisation to help, please reach out to [email protected]!